AI-Native, Not AI-Added: A Builder’s Field Guide to AI You Can Trust

Everyone has an AI demo now. A chatbot that sounds confident, a feature with a sparkle icon, a screenshot that got a thousand likes. The hard part was never the demo. The hard part is building something a real organization can depend on — where a wrong answer carries a real cost, and "it usually works" isn't an answer.
That gap is the whole job. This post is the working vocabulary on the far side of it: the words I use every day building production AI systems, in plain English, organized the way you'd actually build one. Not a glossary to memorize — a map of the decisions that matter, and how I make them.
My north star through all of it: AI-native, not AI-added. These are systems designed around the model from the first line of code — grounded, measured, and governed — not a clever feature bolted onto something that already shipped.
Start with the boring foundation
A large language model (LLM) — Claude, GPT, Gemini — is trained on a vast amount of text and does exactly one thing: predict the next token. A token is the unit it reads and writes, roughly three-quarters of a word. Everything you'll hear about AI cost, speed, and limits is measured in tokens.
The context window is how many tokens the model can hold in mind at once — your instructions, plus any source material you hand it, plus its answer. A bigger window fits more source documents in a single pass. Inference is just the act of running the trained model to get an output; it's the part you pay for every time you use it, as opposed to the one-time cost of training.
One knob worth knowing by name: temperature, a dial from 0 to 1 for randomness. Low temperature is focused and repeatable — what you want for factual, grounded work. High temperature is varied and creative — useful for brainstorming, dangerous for a system that has to be right.
That's the foundation. It's deliberately unglamorous, because the interesting engineering decisions sit one level up.
The first decision: prompting, RAG, or fine-tuning
When someone wants a model to "know" their business, there are three ways to get it there, and the most common mistake is reaching for the heaviest one first. The senior move is the opposite: pick the lightest tool that works.
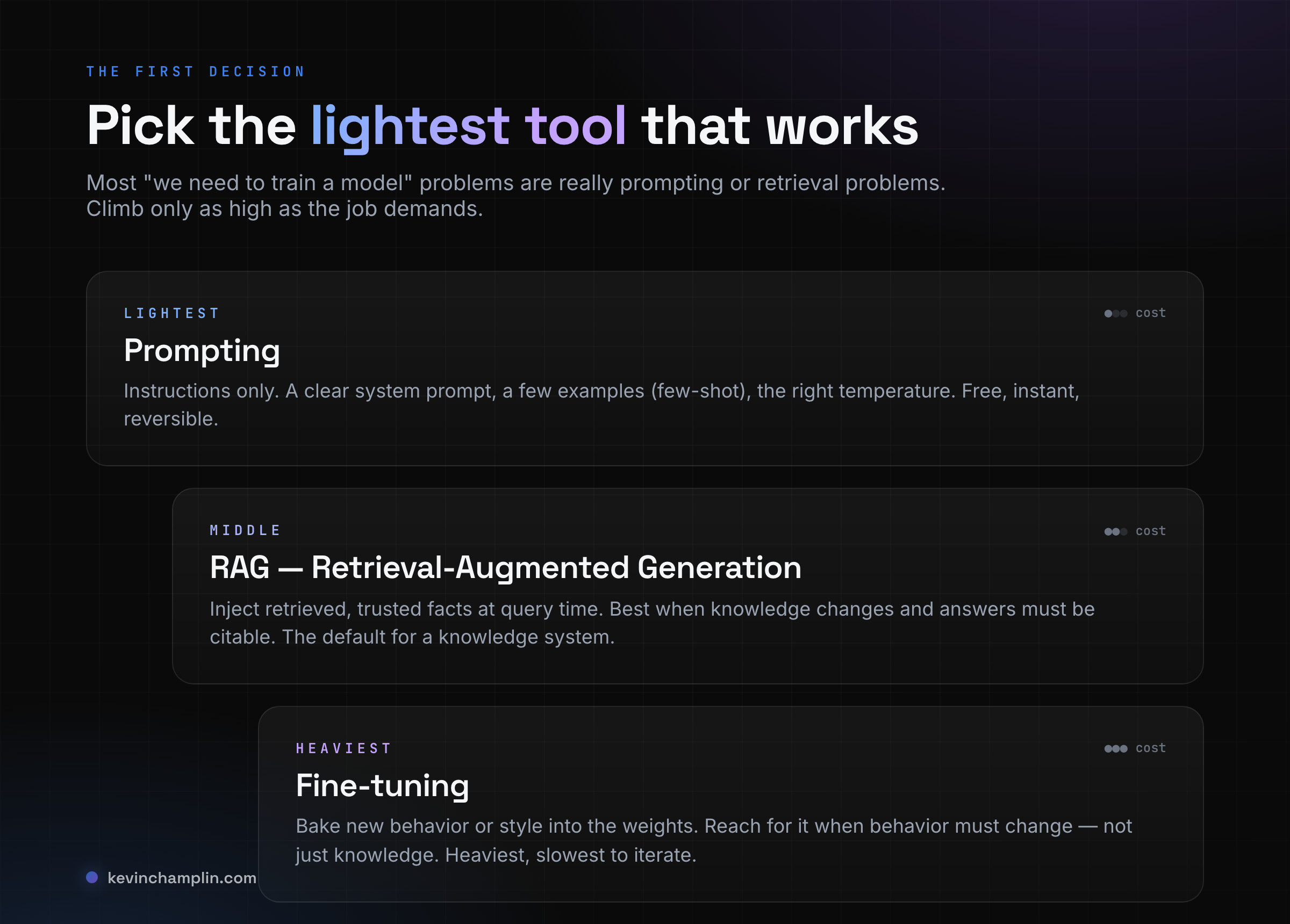
Prompting is instructions only. A clear system prompt — the persistent rules that set the model's role and output format for the whole conversation — plus, when it helps, a few worked examples in the request itself. Asking with no examples is zero-shot; including a handful to steer the format is few-shot. It's free, instant, and reversible. Start here.
RAG — retrieval-augmented generation — injects trusted facts into the prompt at query time. This is the right tool when the knowledge changes, when you need answers tied to specific sources, and when you can't retrain every time a document is updated. For a knowledge system, RAG is the default, and I'll come back to it because it's where most of the real engineering lives.
Fine-tuning means further training the base model on your own data to change how it behaves, not just what it knows. It's the heaviest option and the slowest to iterate on, so I reserve it for when a system's style or behavior has to change in a way prompting can't reach. Knowledge problems are almost never fine-tuning problems.
RAG, done properly
The single biggest risk with an LLM is the hallucination: a confident, fluent answer that happens to be false. You don't fix that by asking the model to try harder. You fix it with grounding — constraining the model to answer only from supplied, trusted sources instead of its own memory. RAG is how grounding gets built.

It starts with ingestion — bringing the source material in. In the real world that means 200-page PDFs, scanned SOPs, web pages, and manuals, which means parsing, OCR, and pulling clean data out of messy tables. Then chunking: splitting those documents into pieces small enough to retrieve precisely but large enough to keep their meaning intact. Each chunk gets an embedding — a numeric vector that captures its meaning, so that pieces about the same idea sit near each other in vector space.
That's what makes semantic search possible: matching a query about "grant renewal" to a passage about "continuation funding" even though they share no keywords. In practice the strongest results come from hybrid search — combining classic keyword scoring with semantic vector search, so you catch both exact matches and meaning. You retrieve the top-k most relevant chunks, then run a reranking pass that re-scores those candidates so the best ones lead before the model ever sees them.
Only then does the model generate an answer — strictly from those retrieved chunks — and it shows its citations: the exact document, section, and version each claim came from. In regulated, high-stakes work, provenance is non-negotiable. And when the answer genuinely isn't in the sources, the right behavior isn't a confident guess. It's refuse-to-guess: the system says "that's not in the sources" and routes to a human. That single behavior is the clearest signal of a trustworthy knowledge tool.
Prove it works — with metrics, not claims
Here's where a lot of AI projects quietly fall apart. They ship on vibes: someone types a few questions, the answers look good, everyone moves on. Then a prompt change three weeks later silently breaks retrieval and nobody notices until a user does.
The fix is an evaluation harness — an automated system that scores outputs against expectations so you catch regressions with data instead of gut feel. You build a ground-truth set: a curated list of real questions with known-correct answers and known-correct sources. You can scale the grading with LLM-as-judge — a strong model applying a fixed rubric to score outputs at volume. And you watch the classic numbers: precision (of what you returned, how much was right), recall (of what was right, how much you returned), and their balance, F1.
Run that continuously and you get regression monitoring — proof that today's change didn't make yesterday's quality worse. Retrieval accuracy stops being a feeling and becomes a number you can defend. "I prove the system works with metrics, not claims" isn't a slogan; it's the difference between a demo and a system you'd stake a contract on.
Where a wrong answer carries real cost
Everything above gets sharper the moment the data is sensitive. If you're working with PII (personally identifiable information) or PHI (protected health information regulated under HIPAA), reliability and security stop being nice-to-haves and become the spec.
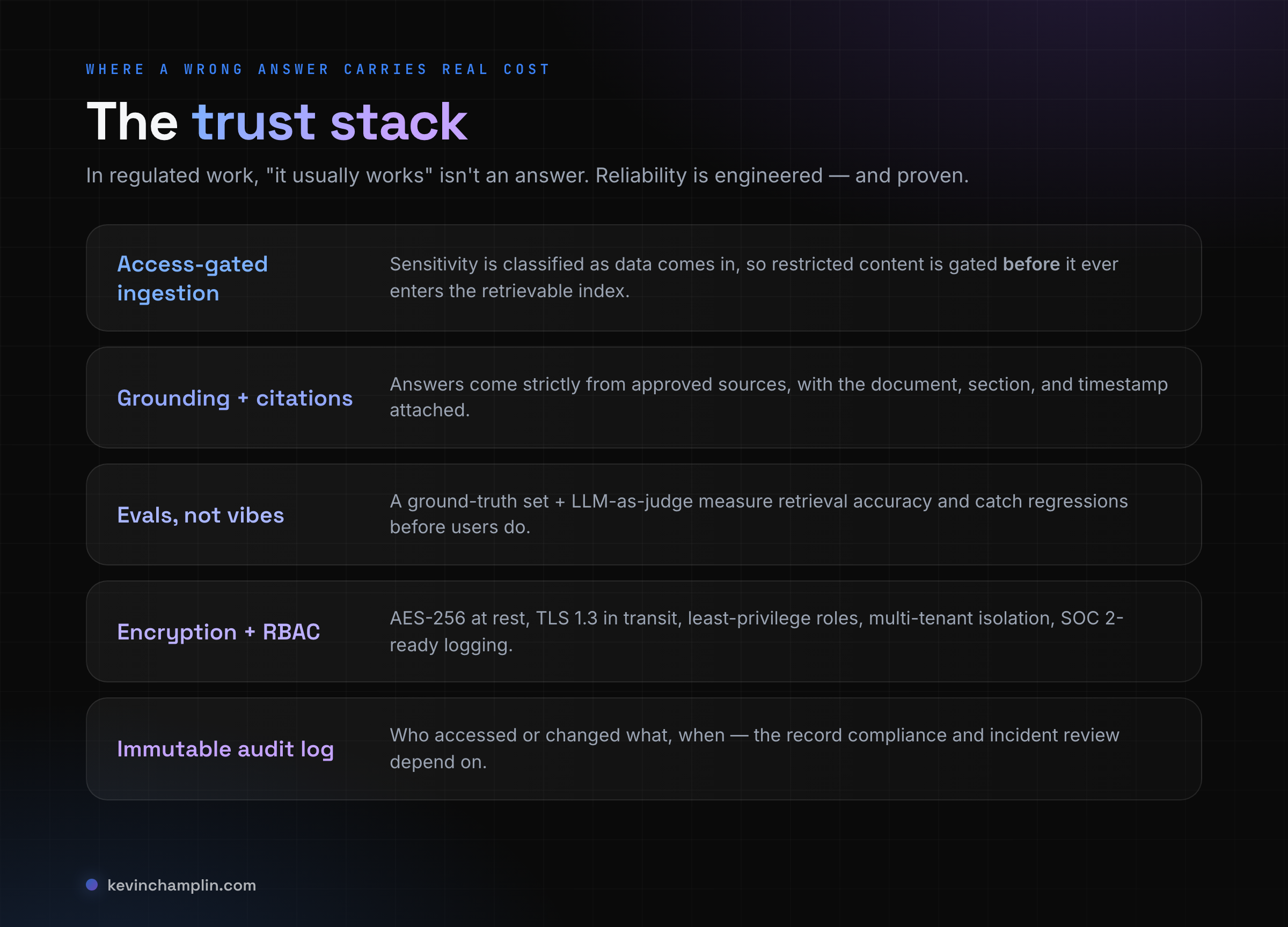
The senior data-handling move happens at the very start of the pipeline: access-gating at ingestion. You classify each document's sensitivity as it comes in, so restricted content is gated before it ever enters the retrievable index — not filtered out hopefully at the end. From there the controls are concrete and worth naming, because naming them signals you actually ship them: encryption at rest (AES-256, so stolen disks are unreadable) and encryption in transit (TLS 1.3, so nothing's intercepted on the wire). Role-based access control (RBAC) and least privilege so every user and service sees only what its job requires. Multi-tenant isolation so one client's data can never cross into another's. And an immutable audit log recording who accessed or changed what, and when — the record that compliance and incident review depend on, and the backbone of being SOC 2-ready.
None of this is exotic. It's the standard of care any serious engineer brings to regulated data — the same instincts that keep a database from leaking, applied to a system that now talks back.
The thing underneath all of it
Strip away the vocabulary and the real differentiator isn't knowing what an embedding is. It's judgment: choosing the lightest tool that solves the problem, grounding answers so they can be trusted, proving quality with numbers, and gating sensitive data before it's ever exposed. The terms are just how engineers talk to each other quickly about those decisions.
When I take on a new system, the approach is always the same shape: audit the current state, propose a scoped, phased plan, get alignment, then ship in increments and prove retrieval quality as I go. It's the opposite of a big-bang rewrite — and it's why these systems hold up when the stakes are real.
The interface will keep changing. New models, new platforms, new buzzwords every quarter. The fundamentals underneath — ingestion, retrieval, prompt design, evaluation, governance — don't. Learn those, and a new tool is just a different keyboard for the same craft.
🔥 A quick aside: I build Hearth — a free, private AI that runs entirely on your own computer, so nothing you type ever leaves your device. Try it free in your browser → (no account, no install), or see how it compares to ChatGPT.
Links mentioned