OpenAI vs Anthropic: Tokens, Models, and What They Really Cost

Everyone’s using AI now. Almost nobody can explain what it costs — or why the same question can cost a tenth of a cent on one model and thirty cents on another. The whole thing runs on a unit most people have never heard of: the token.
This post fixes that. No computer-science degree required. By the end you’ll know what a token is, the difference between OpenAI and Anthropic, which model to reach for, and roughly what each one will cost you. I’ll keep the jargon to a minimum and put the real numbers in plain charts.
First: what’s a token?

An AI model doesn’t see words the way you do. It chops text into little pieces called tokens. A token is usually about four characters — sometimes a whole short word, sometimes part of a longer one. “Cat” is one token. “Login” is often two (“log” + “in”). A handy rule of thumb:
- 1 token ≈ 4 characters ≈ ¾ of a word
- 1,000 tokens ≈ about 750 words ≈ a page and a half
- 1,000,000 tokens ≈ a fat novel
Why should you care? Because tokens are the meter. Every AI company charges by the token, and they charge twice:
- Input tokens — everything you send in: your question, the instructions, any documents or chat history you attach.
- Output tokens — everything the AI writes back.
Here’s the part that surprises people: output is the expensive half — typically about five times the price of input. The AI generating text costs far more than it reading text. So a chatty model that writes long answers can quietly run up a bill.
The two big players
There are many AI companies, but two sit at the front of the pack, and they’re the ones most businesses actually use:
- OpenAI — makers of ChatGPT. Their models are branded GPT (the current line is GPT-5.5, GPT-5.4, and smaller “mini” and “nano” versions).
- Anthropic — makers of Claude. Their models come in three named sizes: Opus (biggest and smartest), Sonnet (the balanced workhorse), and Haiku (small, fast, cheap).
Both companies sell the same shape of product: a top-tier “genius” model, a mid-tier “workhorse” that handles most real work, and a budget model for high-volume, simple jobs. The trick isn’t picking a company — it’s picking the right tier for the task.
Model for model, side by side
Think of each row below as a matched pair — OpenAI’s option next to Anthropic’s in the same weight class.
| Tier | OpenAI | Anthropic | Reach for it when… |
|---|---|---|---|
| Flagship the smartest | GPT-5.5 | Claude Opus 4.8 | The problem is genuinely hard — deep reasoning, long coding sessions, work you want done with little supervision. |
| Workhorse most jobs | GPT-5.4 | Claude Sonnet 4.6 | Day-to-day production work: chatbots, summaries, drafting, most app features. The sweet spot for price and quality. |
| Budget high volume | GPT-5.4 mini / nano | Claude Haiku 4.5 | Simple, repetitive, or huge-volume tasks: sorting, tagging, extraction, quick replies where speed and price beat brilliance. |
A useful mental model: Opus and GPT-5.5 are the senior engineers — you hand them the gnarly problem and trust the result, but they cost more per task. Haiku and the mini/nano models are the sharp interns — fast and cheap, perfect for the simple stuff you’d be crazy to pay a senior to do.
Now the part everyone actually wants: what it costs
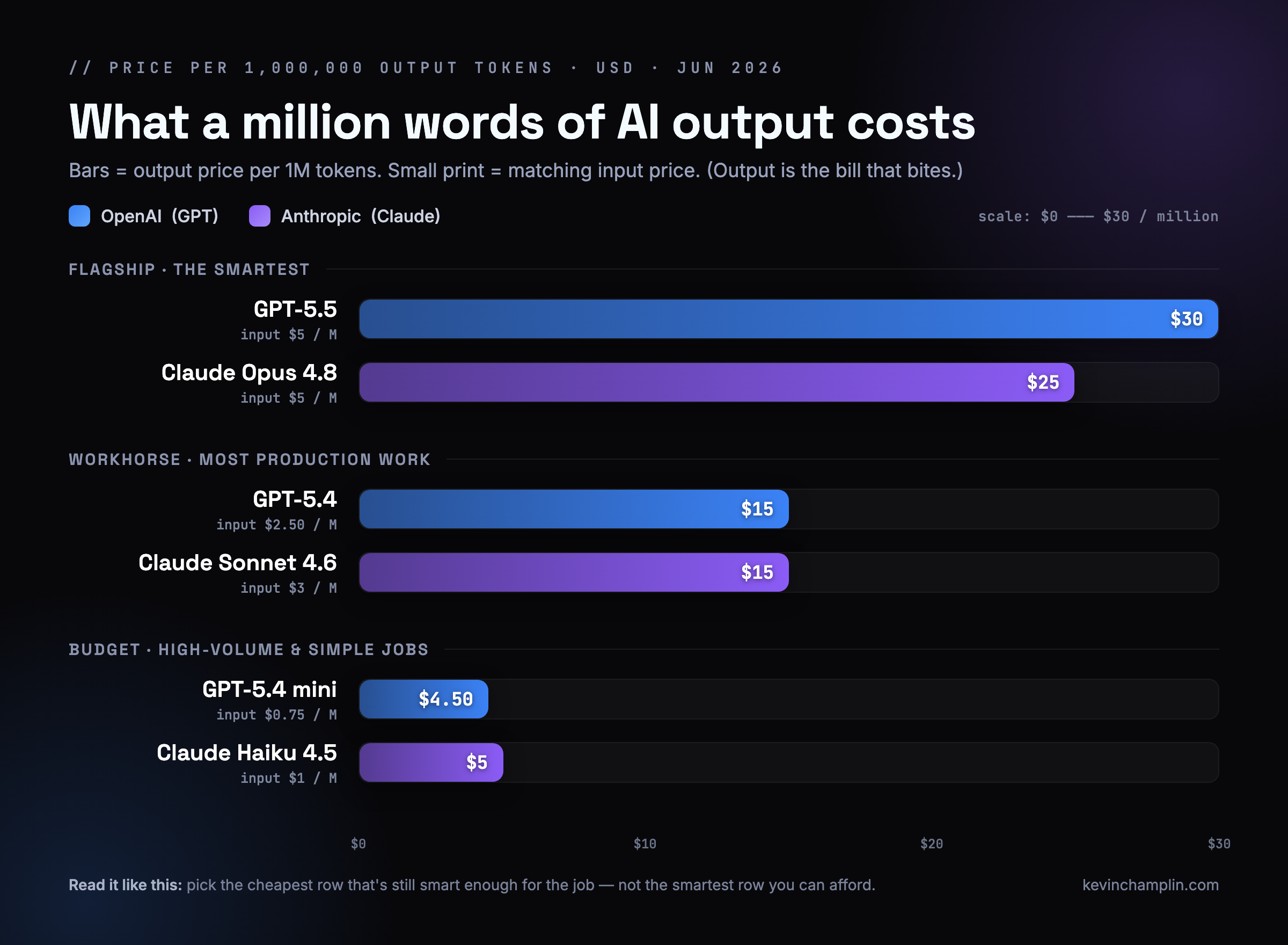
Prices are quoted per million tokens — remember, a million tokens is roughly a fat novel’s worth of text. Here’s the full board as of June 2026:
| Model | Maker | Input ($ / million) | Output ($ / million) |
|---|---|---|---|
| GPT-5.5 | OpenAI | $5.00 | $30.00 |
| Claude Opus 4.8 | Anthropic | $5.00 | $25.00 |
| GPT-5.4 | OpenAI | $2.50 | $15.00 |
| Claude Sonnet 4.6 | Anthropic | $3.00 | $15.00 |
| Claude Haiku 4.5 | Anthropic | $1.00 | $5.00 |
| GPT-5.4 mini | OpenAI | $0.75 | $4.50 |
| GPT-5.4 nano | OpenAI | $0.20 | $1.25 |
Two things jump out. First, the two companies are priced almost identically tier for tier — this is a competitive market, and it shows. Second, the gap between the smart tier and the cheap tier is enormous: Claude Opus 4.8 costs five times what Haiku 4.5 does. Choosing the wrong tier is where money leaks.
A real-world example
Numbers per million tokens feel abstract, so let’s price one actual task: a customer-support reply. Say each reply sends ~3,000 input tokens (instructions + a few past messages + the customer’s question) and writes ~500 tokens back. What does 1,000 of those replies cost?
| Model | Cost per reply | Per 1,000 replies |
|---|---|---|
| Claude Haiku 4.5 | ~$0.0055 | ~$5.50 |
| GPT-5.4 mini | ~$0.0045 | ~$4.50 |
| Claude Sonnet 4.6 / GPT-5.4 | ~$0.016 | ~$16 |
| Claude Opus 4.8 | ~$0.0275 | ~$27.50 |
| GPT-5.5 | ~$0.030 | ~$30 |
Same job, same number of replies — and a 5× to 6× swing depending on the model. For a support inbox handling tens of thousands of messages a month, that’s the difference between a rounding error and a real line item. The skill is matching the model to the difficulty of the task, not just grabbing the smartest one available.
Three things developers should know that the price list won’t tell you
If you’re actually building on these APIs, a few details move the bill more than the sticker price:
- Caching is a 90% discount hiding in plain sight. Both companies let you cache the repeated part of your prompt (a long system prompt, a reference document) so you don’t pay full freight to re-send it every call. A cache hit costs about a tenth of the normal input price. For any app with a big, fixed instruction block, turning this on is the single highest-leverage cost cut available.
- Batch jobs are half price. If a task isn’t time-sensitive — overnight report generation, bulk tagging, processing a backlog — both providers run it asynchronously for a 50% discount on input and output. Free money for anything that can wait a few minutes.
- The sticker price isn’t the whole cost — tokenizers differ. The same paragraph turns into a different number of tokens on different models. Anthropic’s newest models (Opus 4.7 and up) use an updated tokenizer that can produce up to 35% more tokens for the same text. The per-token price didn’t change, but your effective cost per request can. Always test on your real prompts before trusting a back-of-envelope estimate.
So which should you use?
After all the comparison, the honest answer is refreshingly simple:
- Default to the workhorse tier — Claude Sonnet 4.6 or GPT-5.4. It handles the overwhelming majority of real work at a fair price.
- Drop to the budget tier — Haiku 4.5, GPT-5.4 mini/nano — for anything high-volume and simple. This is where you save the most money.
- Reserve the flagship tier — Opus 4.8 or GPT-5.5 — for the genuinely hard problems where a better answer is worth the premium.
- OpenAI vs Anthropic? At these prices it’s rarely about cost — they’re neck and neck. Pick on fit: which one writes in the voice you want, follows your instructions best, and plays nicely with your tools. Many teams quietly use both, routing each job to whichever model wins it.
The headline isn’t “Company A beats Company B.” It’s that understanding tokens turns AI from a mystery bill into a line item you can actually control — and the difference between a careless setup and a thoughtful one is often 5× or more on the same work.
That’s the kind of thing I help companies get right — choosing the right model, wiring up caching and batching, and building AI features that are smart and sustainable. If that’s on your plate, let’s talk.
Prices current as of June 2026, taken from the official Anthropic and OpenAI pricing pages. AI pricing changes often — always check the source before you budget.
Anthropic / Claude pricing OpenAI / GPT pricingLinks mentioned